Posts made by Rob Fitzpatrick
-
Web portal | General Info | Connectionsposted in ~~Bugs~~
I'm looking at the numbers from a client site and they don't make sense to me. At a given time stamp today, I see the following user connection counts:
4GL: 412
batch: 30
remote: 383
self-service: 0I know this client has self-service users. I believe that most if not all of those 30 batch users are also self-service. Looking at historical data, most of the time this database shows zero self-service users, with occasional spikes of 1.
What criteria are used to determine that a client is self-service?

-
Dashboard change?posted in Using ProTop
It seems the dashboard layout changed recently.
I am looking at "Main Dashboard" for a monitored database. I have the following panes:
- Latest Status (13 panels)
- a new unlabelled one that says "CPU: Unknown • Memory: Unknown • OS: Unknown"
- General info (3 panels)
- Database I/O (3 panels)
- Transactions & Locks (3 panels)
- Record activity (3 panels)
- Network metrics (3 panels)
- Async Writers Statistics (3 panels)
There used to be panes for BI and AI info. Have they been relocated? Will they be returning?
-
RE: SQL Servers are double-counted in 3.141xposted in ~~Bugs~~
@tom said in SQL Servers are double-counted in 3.141x:
That's kind of dumb. Who the heck coded that?
casestatements are hard.
-
SQL Servers are double-counted in 3.141xposted in ~~Bugs~~
dc/dashboard.p:
case _Connect-type: ... when "sqsv" then tt_Dashboard.con_sqlServ = tt_Dashboard.con_sqlServ + 1. ... end. //case if _Connect-type begins "SQSV" then tt_Dashboard.con_SQLServ = tt_Dashboard.con_SQLServ + 1.This may also be in previous versions; I haven't checked.
-
RE: Alert re lkHWM near lkTableSizeposted in Using ProTop
@tom said in Alert re lkHWM near lkTableSize:
Regarding the specific alert: there is a lkTblPct field which I use for a similar purpose. Rather than the HWM it reflects the locks in use at that moment. In some ways that is better -- the HWM sticks around until you restart and if something went bump in the night is going to keep alerting once you hit the threshold.
Good to know, thanks.
-
Alert re lkHWM near lkTableSizeposted in Using ProTop
Maybe this belongs in "Roadmap" rather than "Using", but anyway...
Looking at alert.cfg:
# # Metric Type Compare Target Sensitivity Notify Message Action # ====== ==== ======= ====== =========== ====== ==================== ======================= # LogRd num > 100000 3:5 Always "Hit Ratio &1 &2 &3" alert-message,alert-log # # Metric The ui-det name of the field being monitored. # # Type Data type -- char or num (string or numeric). # # Compare Operator -- >, <, =, <>, <=, >= # # Target The threshold value of the metric to be tested.Since it isn't stated explicitly, does "Target" have to be a constant? Could it be another metric of the same data type as "Metric"? Or an expression on constants or metrics (e.g. lkHWM * 0.8)?
Use case: let's say I want to configure an alert to fire when the lock HWM is getting close to -L, and have it work regardless of the value of -L, which could possibly vary over time or from one DB to another. Is that possible? Or do I just need to decide which number (say, 7000) I care about and configure it to alert when lkHWM > 7000?
Food for thought: the alerting mechanism would become more powerful if the target values could be dynamic in some way. Maybe passed to the back end via the API.
-
RE: Web portal Alerts Feedposted in Using ProTop
Cool, thanks.
Do you similarly flag tables where table reads are very high compared with the reads of their indexes? The calculations would be more involved but it might be useful.
-
RE: Report inactive indexesposted in Roadmap
For reference, the non-essential audit indexes (which are often purposely deactivated, except in audit archive DBs):
_aud-audit-data._AppContext-Id
_aud-audit-data._Connection-id
_aud-audit-data._Event-context
_aud-audit-data._Event-group
_aud-audit-data._EventId
_aud-audit-data._Userid
_aud-audit-data-value._Field-name
-
RE: Release 3.141 is drawing nigh!posted in Roadmap
Possible bug: "%" must be invoked twice to have effect
I start pt3.141x against a DB, and Sample Type is "Rate/Interval" (as expected). When I hit "%" and select "Raw/Summary" and F1, the stats don't change. It says "RAW Summary" at top left but the stats are still interval rates. Hitting spacebar to refresh doesn't help. When I hit "%" and select "Raw/Summary" and F1 a second time, the raw stats appear as expected.
It appears this is the case for any changes in Sample Type. Changing back from "Raw/Summary" to "Rate/Interval" has the same issue, as does changing to "Cumulative/Summary".
-
RE: User "batch" displayed as "local"posted in Using ProTop
Ok...
Do something different. (Please.)

-
User "batch" displayed as "local"posted in Using ProTop
From lib/vstlib.p:
if u_name = "batch" then u_name = "local".Why?
I ask because we have applications where there are batch clients with user names like batch, batch2, batch3. PT displays them as local, batch2, batch3. It seems an arbitrary change and there is no code comment about it.
Was this added to deal with a past Progress behaviour? Or some vendor application?
-
Web dashboard info cut offposted in ~~Bugs~~
The Alerts Feed and Critical Alerts panes each have three columns of information. They don't have column headers but let's call them Time of Day, Resource Name, and Alert Details. When you hover over the alert, a "window" pops up with additional details about the alert.
The issue is that the right edge of this window is aligned always to the left of the Alert Details column. So in the case where the pane is either on the left side of the dashboard or it is maximized, about half of the pop-up window is cut off so its content can't be read. This makes the ability to drag these panes to the left side of the dashboard, or to maximize them, useless.
Example:
In cases where the pop-up window would otherwise extend past the left side of the display, it would be preferable its alignment was changed to align its left side with the left side of the display, rather than aligning its right side with the Alert Details column.
-
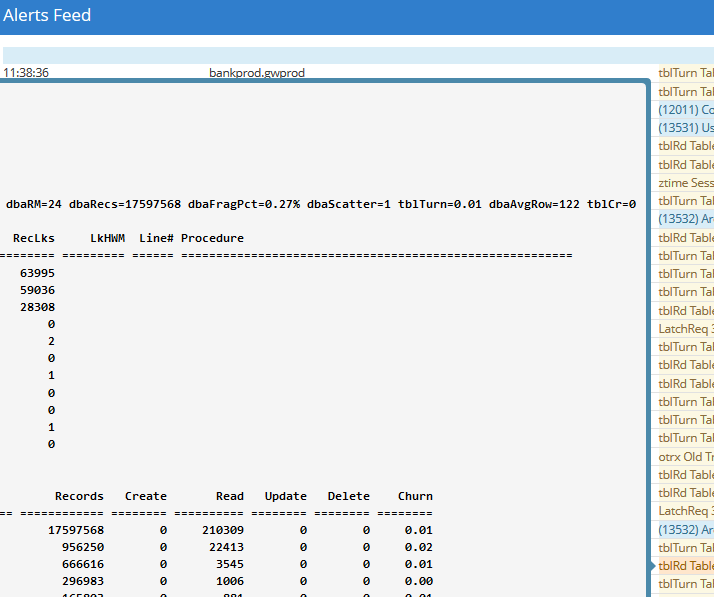
Web portal Alerts Feedposted in Using ProTop
I'm looking at alerts in the Alerts Feed and their accompanying tooltips or pop-ups or whatever those boxes are called that you see when you hover over an alert.
One alert was like "tblRd Table reads/sec x > y". The pop-up has some header info, followed by a table of users by logical reads and tables of table and index CRUD. Some of the table CRUD line items end with "***", to the right of the "Churn" column.
In my browser (Firefox), these pop-up boxes are very finicky. It is sometimes difficult to make them appear by hovering over the alert, and when they do they sometimes disappear after some period that I can't discern.
Questions:
- What is the meaning of the three asterisks beside a table record?
- Are there any ProTop UI configuration settings that govern the behaviour of these pop-up boxes?
-
Report inactive indexesposted in Roadmap
I was looking through ProTop and was somewhat surprised to find that it doesn't seem to report inactive indexes anywhere. Just wondering whether that has been considered as a feature, e.g. as a counter (# of inactive indexes) in the configuration panel.
Given the performance problems that an inactive index could cause, it would be useful to alert if this number was non-zero (perhaps excluding audit indexes).
-
RE: OE 12 supportposted in Using ProTop
@tom said in OE 12 support:
Lastly, I also (sneakily) patched the pt3.14 release a week or so ago. If your "as of" date on that is in May rather than March then you should also have the oe12 changes (but not the "4" hotkey).
That explains it, I got the error from the original March version.
-
RE: Configure the User Information Viewerposted in Using ProTop
@tom said in Configure the User Information Viewer:
I'm thinking that the statement cache should automatically appear or disappear based on whether or not it is enabled for a particular client.
That's reasonable. Though I'd still like to be able to turn the individual browses on or off.
")
It would also be nice to have the act of turning off User Information Viewer revert to a view that is more useful, as opposed to just removing the header section. E.g. if the act of going into it cached the current list of displays (e.g. d, t, i, u), so they could be restored when u is pressed again. Food for thought.